
나의 개발일지
[1181] 단어 정렬 - 정렬, 문자열, Comparator (백준, Java) 본문
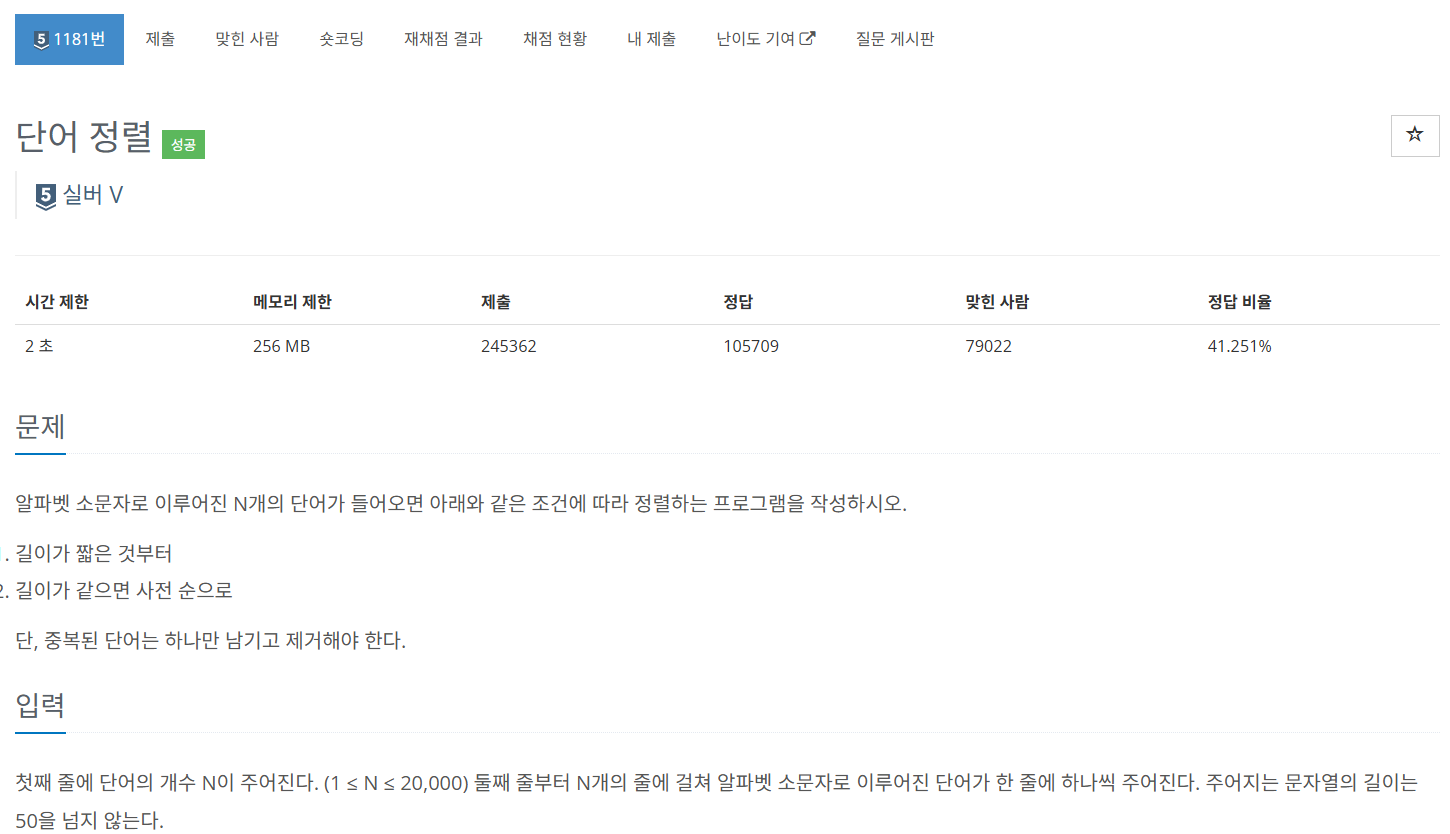

처음에는 Map 자료구조를 이용해서 key 값으로 입력받은 단어의 길이, value 값을 list형태로 같은 길이의 문자들을 사전 순 정렬해서 넣으려고 했었다.
이렇게 할 경우 list.contains() 로 같은 단어가 있는지를 계속 확인을 하며 중복을 제거해야 했다.
-> 리스트의 크기가 커질수록 contains()로 비교하면 속도가 느려진다.
또한 Map 안에서 key 값인 단어 길이 수를 정렬하는 작업이 필요해서 비효율적이다.
따라서 다른 방법을 찾아보다가 Comparator에 대해 알게 되었다.
예전에도 종종 써본 적은 있는데 확실한 개념을 모르고 있었던 것 같아 (그러니까 생각이 안 났..) 다시 정리해보려고 한다.
- Comparable : 객체 자기 자신의 기본 정렬 기준을 정의
객체에서 Comparable인터페이스를 구현하여 정렬 기준을 정함.
public int compareTo(T o) 메소드를 오버라이딩 하여 this (객체 자신)와 o (외부 객체)를 비교한다.
String, Integer 등 표준 클래스에 이미 구현 되어있음
다음과 같이 사용할 수 있다.
public class Product implements Comparable<Product> {
private int price;
@Override
public int compareTo(Product other) {
return this.price - other.price; // 오름차순
}
}
- Comparator : 외부에서 커스텀 정렬 기준을 정의
이미 정해진 기본 기준 외에 다른 기준으로 정렬하고 싶거나, 수정할 수 없는 클래스(String 등)을 정렬할 때 사용한다.
public int compare(T o1, T o2) 메소드를 오버라이딩 하여 사용.
다음과 같이 사용할 수 있다.
Comparator<String> lengthComparator = new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
return s1.length() - s2.length();
}
};
* compareTo와 compare 메소드에서 return 된 값에 따른 결과
- 음수일 경우 : 앞의 값이 작음 == 순서 유지
- 0 : 두 값이 같음 == 순서 유지
- 양수일 경우 : 뒤의 값이 작음 == 순서 바뀜
return o1 - o2 이면 오름차순, return o2 - o1는 내림차순 정렬이 된다.
o1 - o2에서 양수가 나오면 o1 > o2 라는 의미이고 그럼 자리가 swap되니까 결국 작은 수가 앞으로 오게 된다.
o2 - o1에서 양수가 나오면 o1 < o2 라는 의미이고 그럼 자리가 swap되니까 결국 큰수가 앞으로 오게 된다.
이 Comparator을 해당 문제에 적용해보겠다.
(Comparator을 택한 이유는 String 클래스는 내가 수정할 수 없기 때문에 이번에만 특수한 기준으로 정렬하려고 하기 위함)
문제에서 아래와 같이 나와있다.
- 길이가 짧은 것부터
- 길이가 같으면 사전 순으로
단, 중복된 단어는 하나만 남기고 제거해야 한다.
일단 중복 단어를 제거하기 위해 list가 아닌 set 자료구조를 이용해 단어들을 저장하기로 한다.
Set<String> set = new HashSet<>();
Collections.sort로 정렬하기 위해 단어들을 저장하고 list로 변경한다.
HashSet은 순서가 없으므로 Collections.sort를 이용하기 위해서는 필수이다.
List<String> list = new ArrayList<>(set);
Comparator의 compare메소드를 이용해 내가 정한 규칙을 적용한다.
compare(String o1, String o2) {
if (o1.length() != o2.length()) { // 길이가 다를 경우
return o1.length() - o2.length();
}
return o1.compareTo(o2); //길이가 같을 경우 사전 순
}
두번째 return 값은 뭔가 싶을 수 있는데 o1이 String이므로 해당 클래스의 compareTo 메소드를 사용한 것이다 !
아까 개념 정리 할 때 Comparable 인터페이스의 compareTo는 String 같은 표준 클래스에 이미 구현이 되어있다고 했다.
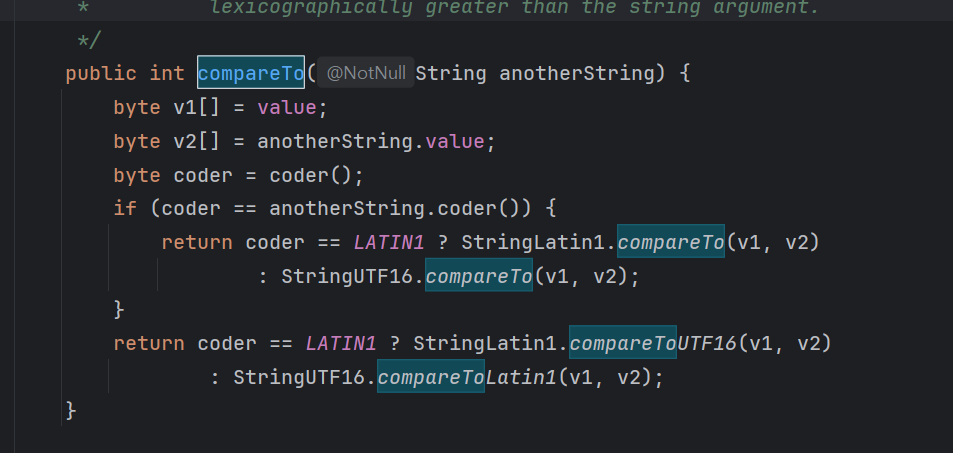
실제로 String 클래스의 내부를 확인해보면 이렇게 되어있다.
byte 배열은 자바에서 메모리 효율을 위해 문자열을 다루는 배열이다.
코드를 보면 v1로 자기 자신, v2로 다른 문자열을 영어인지, 한글인지에 따라 compareTo를 호출하여 비교하는 로직이다.
따라서 손쉽게 사전 순 정렬을 할 수 있게 된다 !
전체 코드는 다음과 같다.
단어가 많을 경우 효율을 위해 StringBuilder를 사용해서 정렬된 결과를 넣고 마지막에 System.out.println()을 사용해 한 번에 출력하도록 하였다.
전체 코드
import java.util.*;
import java.io.*;
class Main {
public static void main(String[] args) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
Set<String> set = new HashSet<>();
for (int i = 0; i < N; i++){
set.add(br.readLine());
}
List<String> list = new ArrayList<>(set);
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
if (o1.length() == o2.length()) {
return o1.compareTo(o2);
} else {
return o1.length() - o2.length();
}
}
});
StringBuilder sb = new StringBuilder();
for (String s : list){
sb.append(s).append("\n");
}
System.out.println(sb.toString());
}
}
101665043 : StringBuilder 사용했을 때
101654714 : StringBuilder 사용하지 않았을 때