일정 목록을 조회하는 API를 구현함에 있어서 정말 복잡하게 테이블을 조회해야하는 일이 생겼다.
전체 ERD 중 일정 생성에 연관된 테이블은 다음과 같다.
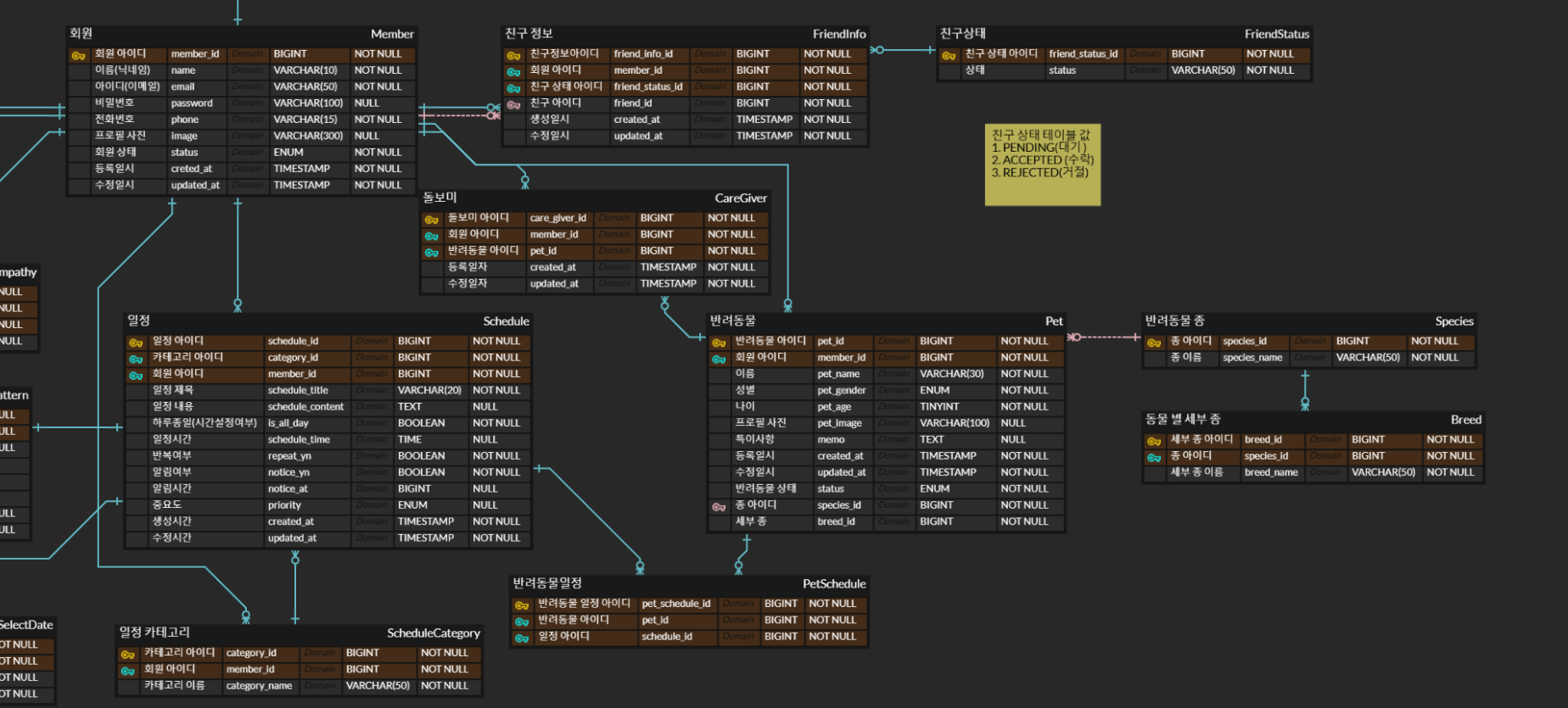
일정 목록 조회를 위해서는 다음과 같은 조회 쿼리가 필요하다.
그에 대한 이유도 각각 아래 서술한 것과 같다.
1. 로그인한 사용자가 만든 일정 조회
-> 반려동물이 없는 일정도 조회하기 위함
2. 로그인한 사용자가 돌보미로 등록된 반려동물의 일정 조회
3. 로그인한 사용자가 소유한 반려동물의 일정 조회
-> 자신의 반려동물이지만 돌보미로 등록된 다른 사용자가 만든 일정 정보 획득
이렇게 조회를 한 후 중복을 제거하면 관련된 모든 일정에 대해 조회가 가능하다.
시도해봤던 로직
1. 로그인한 사용자가 만든 일정 + 로그인한 사용자가 돌보미로 등록된 펫의 일정
- 이 때의 문제점 : 내 펫이지만 돌보미로 등록된 사용자가 만든 일정은 조회가 안 됨.
2. 로그인한 사용자의 반려동물이 포함된 일정 + 로그인한 사용자가 돌보미인 펫 일정
- 문제 1 : 초기에 각각을 pageable을 파라미터로 넣고 Page<?> 형태로 조회해 왔는데 이러면 데이터 손실이 났음.
-> 파라미터를 pageable.unpaged()로 보내거나 or List로 조회 데이터를 처리한 다음 최종적으로 PageImpl<>로 처리.
후자 선택
- 문제 2 : 내 펫과 내가 돌보미로 등록된 펫이 한 번에 포함된 일정일 경우 조회 결과가 중복되는 문제
-> 내 펫의 일정id List , 내가 돌보미 펫 일정id List를 Set<Long>에 저장하여 중복을 제거함
- 문제 3 : Set<Long> 로 중복을 제거한 일정에서 아이디만 받아왔지만 이 일정 아이디들로 어차피 schedule 엔티티를 또 조회해야하고 위에서 pet을 각각 조회했지만 해당 일정에 엮인 펫 정보를 또 조회해야함. -> 불필요한 조회 발생
+ List로 데이터를 여러 번 조회하며, stream과 flatMap을 반복적으로 사용
findPetIdsByMember → findScheduleIdByPet → findById 이런 연속적인 호출은 N+1 문제 발생 가능
문제 3을 가지고 있었지만 작성한 코드는 다음과 같다.
public void test(MemberAdapter memberAdapter) {
Member member = getMemberByMemberAdapter(memberAdapter);
List<Schedule> scheduleList = scheduleRepository.findByMember(member);
//로그인한 사용자의 펫 List
List<Pet> myPetList = petRepository.findByMember(member);
// 돌보미 펫 List
List<Pet> careGiverPetList =
careGiverRepository.findByMember(member).stream()
.flatMap(cg -> petRepository.findByPetId(cg.getPet().getPetId()).stream())
.toList();
//로그인 한 사용자의 펫이 있는 일정 아이디
List<Long> userPetSchedules =
petRepository.findPetIdsByMember(member.getMemberId())
.stream()
.flatMap(petId -> petScheduleRepository.findScheduleIdByPet(petId).stream())
.toList();
//로그인 한 사용자가 돌보미인 펫의 일정 아이디
List<Long> careGiverPetSchedules =
careGiverRepository.findPetIdsByMember(member.getMemberId())
.stream()
.flatMap(petId -> petScheduleRepository.findScheduleIdByPet(petId).stream())
.toList();
// Set으로 합치기
Set<Long> scheduleIds = new HashSet<>();
scheduleIds.addAll(userPetSchedules);
scheduleIds.addAll(careGiverPetSchedules);
//Set을 Page<dto> 형태로 변환
// set<scheduleId>를 -> list<dto>
List<ScheduleListResponse> scheduleListResponseList =
scheduleIds.stream().map(id -> // 일정 하나당 실행
{
Optional<Schedule> schedule = scheduleRepository.findById(id);
List<PetSchedule> petSchedules = petScheduleRepository.findBySchedule(schedule.get());
List<Long> petIds = petSchedules.stream()
.filter(ps -> myPetList.contains(ps.getPet())
|| careGiverPetList.contains(ps.getPet()))
.map(ps -> ps.getPet().getPetId())
.toList();
List<String> petNames = petSchedules.stream()
.filter(ps -> myPetList.contains(ps.getPet())
|| careGiverPetList.contains(ps.getPet()))
.map(ps -> ps.getPet().getPetName())
.toList();
//petSchedule을 Set으로 바꾸고 findBy를 뭐 어케 조건을 걸어서 member caregiver인지
return schedule.get().toListDto(petSchedules, petIds, petNames);
}).toList();
// 반려동물 없이 만든 일정은 조회되지 않음.
return new PageImpl<>(scheduleListResponseList, pageable, scheduleListResponseList.size());
}1. 로그인 한 사용자의 반려동물 리스트(myPetList)를 가져오고 사용자가 돌보미로 등록된 반려동물 리스트(careGiverPetList)를 가져온다.
2. myPetList에 관련된 일정 아이디를 가져오고(userPetSchedules) careGiverPetList에 관련된 일정 아이디를 가져온다.(careGiverPetSchedules)
3. 이렇게 가져온 일정 리스트들을 중복이 없도록 Set 자료구조로 합친다. (scheduleIds)
4. scheduleIds를 응답 dto 형태로 변경시킨다.
이 와중에 각 일정에 대해 pet 정보를 또 조회해서 petId와 Name을 리스트로 조회해서 넣는다.
이렇게 만들었지만 ..!
API 테스트 결과 반려동물을 기준으로 일정을 가져오기 때문에 반려동물 없이 생성한 일정은 조회되지 않는다.
(일정을 기준으로 조회를 하는 로직도 작성해보았지만 문제가 많아서 기각했던 상태..)
또한 N + 1 문제가 발생할 수 있다.
N + 1 문제란 ? )
엔티티 조회 시 연관관계에 있는 엔티티가 의도치 않게 조회되는 현상
N + 1 문제와 해결 방법 Fetch Join, Batch Size, Entity Graph
N + 1 문제와 해결 방법 Fetch Join, Batch Size, Entity Graph
DB에서 정말 빈번하게 발생하는 N + 1문제를 인식하고 (드디어) 이해를 해서 포스팅을 해보려고 한다. N + 1 문제란 ?ORM (Object Relational Mapping)을 사용할 때 발생할 수 있는 비효율적인 데이터베이스
soni-developer.tistory.com
그래서 정리한 3가지의 경우가 다음과 같아졌다.
1. 로그인한 사용자가 만든 일정 조회
2. 로그인한 사용자가 돌보미로 등록된 반려동물의 일정 조회
3. 로그인한 사용자가 소유한 반려동물의 일정 조회
1. 로그인한 사용자가 만든 일정 조회
List<Schedule> ownScheduleList =
scheduleRepository.findByMember(member);
2. 로그인한 사용자가 돌보미로 등록된 반려동물의 일정 조회
List<Schedule> scheduleList =
scheduleRepository.findByAllSchedule(member.getMemberId());@Query("select s from Schedule s" +
" join PetSchedule ps ON s.scheduleId = ps.schedule.scheduleId" +
" join Pet p ON p.petId = ps.pet.petId" +
" join CareGiver cg ON cg.pet.petId = p.petId" +
" where cg.member.memberId = :memberId")
List<Schedule> findByAllSchedule(@Param("memberId") Long memberId);
3. 로그인한 사용자가 소유한 반려동물의 일정 조회
List<Schedule> ownPetScheduleList =
scheduleRepository.findByPetSchedule(member.getMemberId()); @Query("select s from Schedule s" +
" join PetSchedule ps on ps.schedule.scheduleId = s.scheduleId" +
" join Pet p on p.petId = ps.pet.petId" +
" where p.member.memberId = :memberId")
List<Schedule> findByPetSchedule(@Param("memberId") Long memberId);
1~3 과정을 거치면 로그인한 사용자와 관련된 모든 일정 목록을 List에 담을 수 있다. (중복이 존재할 수 있음)
이걸 Set 자료구조에 담아 중복을 제거해준다.
Set<Schedule> distinctSchedule = new HashSet<>();
distinctSchedule.addAll(ownScheduleList);
distinctSchedule.addAll(scheduleList);
distinctSchedule.addAll(ownPetScheduleList);
그리고 응답 ListDto형태로 변환해준다.
List<ScheduleListResponse> responseList = new ArrayList<>();
for (Schedule schedule : distinctSchedule) {
List<Pet> petList = new ArrayList<>();
for (PetSchedule ps : schedule.getPetSchedules()) {
if (petRepository.existsByPetIdAndMember(ps.getPet().getPetId(), member) ||
careGiverRepository.existsByPetIdAndMember(ps.getPet().getPetId(), member.getMemberId())) {
petList.add(ps.getPet());
}
}
responseList.add(schedule.toListDto(petList));
}
return new PageImpl<>(responseList);
위의 for문으로 작성된 코드를 가독성있게 stream으로 만들어보았다 !
List<ScheduleListResponse> responseList = distinctSchedule.stream().map(schedule -> {
List<Pet> petList = schedule.getPetSchedules().stream()
.map(PetSchedule::getPet)
.filter(pet -> petRepository.existsByPetIdAndMember(pet.getPetId(), member) ||
careGiverRepository.existsByPetIdAndMember(pet.getPetId(), member.getMemberId()))
.toList();
return schedule.toListDto(petList);
}).collect(Collectors.toList());
짠 ! 이렇게 JPQL을 이용해서 일정 목록을 불러올 수 있는 로직을 작성하였다.
정리

위와 같이 레포지토리의 메소드 위에 @Query를 사용해 sql문을 직접 작성하는 것을 JPQL이라고 한다.
JPQL이란 ?
Java Persistence Query Language의 약자로 JPA(Java Persistence API)에서 엔티티를 대상으로 쿼리를 작성하는 객체지향 쿼리 언어이다.
SQL 문법과 유사하지만 DB 테이블이 아니라 JPA 엔티티를 대상으로 쿼리를 작성한다.
JPQL 특징
- JPA가 제공하는 기능이라 특정 DBMS에 종속되지 않고 이식성이 높다.
- 테이블이 아닌 엔티티를 기반으로 작성되므로 객체 지향적인 개발에 적합하다.
- JPQL은 실행 시점에 SQL로 변환해 DB에 전달한다.
JPQL 장점
1. 객체지향적 접근
- SQL은 테이블 중심으로 작성되지만 JPQL은 엔티티와 객체 필드를 활용하여 작성된다.
- 개발자가 DB 테이블이 아닌 도메인 모델 (엔티티)를 중심으로 생각할 수 있다.
2. DBMS 독립성
- JPQL은 특정 DBMS에 종속되지 않아 이식성이 높다. db를 교체해도 쿼리를 수정할 필요가 거의 없다.
3. 자동화된 변환
- JPQL 쿼리는 실행 시점에 적절한 SQL로 변환된다. 개발자는 SQL 작성의 복잡성을 줄일 수 있다.
4. JPA와의 통합성
- JPQL은 JPA의 엔티티 매핑과 밀접하게 통합되어 동작하며, 지연로딩이나 캐싱과 같은 JPA 이점을 그대로 사용할 수 있다.
JPQL 단점
1. 복잡한 쿼리를 작성하기 어려움
- JPQL은 복잡한 비즈니스 로직이나 데이터 처리 (복잡한 JOIN이나 서브쿼리) 등에는 적합하지 않을 수 있다.
- 복잡한 SQL 쿼리 작성에는 SQL 자체를 사용하는 것이 유리
2. 성능 이슈
- JPQL은 SQL로 변환되기 때문에, 최적화가 필요한 고성능 쿼리 작성 시 제약이 있을 수 있다.
- DB특화 기능( ex 특정 함수 호출, 인덱스 힌트 등)을 사용할 수 없다.
3. 디버깅 및 튜닝 어려움
- JPQL은 내부적으로 SQL로 변환되기 때문에, 실제로 실행된 SQL 쿼리를 확인하거나 디버깅하는데 추가 작업이 필요하다.
- 복잡한 JPQL을 작성할 경우, 변환된 SQL이 비효율적일 가능성이 있다.
사용 시 주의할 점
1. 엔티티 중심 설계
- JPQL은 반드시 엔티티를 대상으로 동작한다. 테이블이 아닌 엔티티에 매핑된 필드를 사용해야한다.
2. 지연로딩과의 관계
- JPQL 쿼리를 사용할 때, 연관된 엔티티가 LAZY로 설정되어 있으면 추가 쿼리가 발생할 수 있음(N + 1 문제 가능성)
- 필요한 경우 FETCH JOIN이나 @EntityGraph 사용
3. JPQL로 해결하기 어려운 경우 Native Query 사용
- 복잡한 로직이 필요하거나 DBMS 고유의 기능을 사용하는 경우, 네이티브 쿼리(@Query(nativeQuery = true)를 사용하는 것이 적합하다.
* Native Query란 ?)
JPA에서 JPQL대신 SQL 문법 그대로 사용할 수 있는 쿼리.
JPQL은 객체 지향적인 쿼리 언어이지만 네이티브 쿼리는 DB에 종속된 SQL 쿼리를 작성하여 실행한다.
네이티브 쿼리를 사용하려면 @Query 또는 EntityManager 활용
1. @Query(nativeQuery = true) -> 쿼리 결과는 JPA가 매핑된 엔티티로 반환.
2. EntityManager의 createNativeQuery 메소드 통해 실행 -> 반환값은 객체 배열(Object[])로 제공되며 수동 매핑 필요
JPQL로 작성하기 어려운 복잡한 쿼리(여러 테이블의 조인, 그룹화, 집계함수 등)을 작성할 수 있음
| 구분 | 네이티브 쿼리 | JPQL |
| 쿼리 언어 | SQL | 객체 중심 JPQL |
| DB 독립성 | 낮음(DBMS 종속) | 높음 |
| 복잡한 쿼리 처리 | 가능 | 제한적 |
| DB 고유 기능 활용 여부 | 가능 | 불가 |
| 자동 매핑 | 엔티티 자동 매핑 x (수동 매핑 필요 가능성) | 엔티티 자동 매핑 o |
| 성능 최적화 | SQL 최적화 가능 | JPQL 자체는 최적화 한계 |
| 학습 난이도 | SQL 사전 지식 필요 | JPA 내부의 객체 지향적 쿼리 작성 |
+ 이전에 내가 JPQL로 Repository에 만들어둔 메소드 중에 틀린 게 있어 정정 !
JPQL은 엔티티를 기반으로 쿼리를 작성해야하는데 내가 사용한 코드를 보면 아래와 같이 JOIN ~~ ON을 쓴다.
@Query("select s from Schedule s" +
" join PetSchedule ps ON s.scheduleId = ps.schedule.scheduleId" +
" join Pet p ON p.petId = ps.pet.petId" +
" join CareGiver cg ON cg.pet.petId = p.petId" +
" where cg.member.memberId = :memberId")
List<Schedule> findByAllSchedule(@Param("memberId") Long memberId);
그럼에도 정상동작하는데 JPA가 JPQL을 SQL로 변환하면서 SQL 문법을 허용한 것으로 보인다.
ON은 SQL 문법에서 사용하는 구문으로 JOIN절의 조건을 명시한다.
JPQL에서는 연관관계 매핑을 (@ManyToOne, @OneToMany) 사용하므로 명시적인 ON이 필요하지 않다.
(두 엔티티 간에 연관관계 매핑이 없으면 ON 절을 사용할 수 있다.)
실제로 아래처럼 제거해도 정상동작한다 !
@Query("select s from Schedule s" +
" join PetSchedule ps" +
" join Pet p" +
" join CareGiver cg" +
" where cg.member.memberId = :memberId")
List<Schedule> findByAllSchedule(@Param("memberId") Long memberId);
엥 3개의 메소드 모두 ON 제거하니까 아래와 같은 오류가 나서 한 메소드씩 다시 원래대로 돌려봤는데 결국 세 개 중 어떤 것도 ON을 사용 안 하면 오류가 난다 ..... 일단 ON 을 사용한 JPQL문으로 .. 작성..
@Query("select s from Schedule s" +
" join PetSchedule ps ON s.scheduleId = ps.schedule.scheduleId" +
" join Pet p ON p.petId = ps.pet.petId" +
" join CareGiver cg ON cg.pet.petId = p.petId" +
" where cg.member.memberId = :memberId")
List<Schedule> findByAllSchedule(@Param("memberId") Long memberId);
이렇게에 ~... JPQL을 이용한 다중 테이블 조인 ! 완성
'프로젝트' 카테고리의 다른 글
| GiftFunding) Redisson을 이용한 동시성 이슈 제어 (0) | 2024.05.30 |
|---|---|
| GitHub Actions vs Jenkins (0) | 2024.04.23 |
| GiftFunding) TroubleShooting - Member API 컨트롤러 테스트 중 401 에러 (1) | 2024.04.18 |
| GiftFunding) Service 테스트 코드 작성하기 (0) | 2024.04.17 |
| GiftFunding) RestDocs + Swagger 적용하기(feat. Controller 테스트 코드 작성) (0) | 2024.04.13 |

