
나의 개발일지
스프링 핵심가이드) 북스터디 3주차 : 06장 본문
06 데이터베이스 연동
6.1 마리아DB설치
실무에서는 root 계정 사용하지 않음.
문자 인코딩 방식 UTF-8 설정 : Use UTF8 as default server's character set에 체크
GUI도구 : HeidisSQL
6.2 ORM
ORM(Object Relational Mapping) : 객체 관계 매핑
자바와 같은 객체지향 언어에서 의미하는 객체와 RDB(Relational Database)의 테이블을 자동으로 매핑하는 방법
Persistance : 영속성. 데이터를 생성한 프로그램이 종료되어도 데이터는 남아있는 것 -> DB
Persistance Framework : 영속성을 가진 DB와 Spring Boot를 이어주는 것
- 종류 : SQL Mapper, ORM
- SQL Mapper : 쿼리를 직접사용하여 쿼리와 객체 연결 -> JDBC
- ORM : 쿼리를 직접 사용하지 않고 DB테이블과 객체를 연결 -> JPA
- JDBC : SQLMapper의 하나로 Java와 DB를 단순 연결. 쿼리를 작성해서 사용.
-JPA : 자바에서 ORM을 쓰기위한 인터페이스의 모음으로 DB테이블과 자바의 객체를 연결해주면 쿼리가 자동 생성.
- ORM의 장점 : 쿼리문이 아닌 코드(메소드)로 데이터 조작
·ORM을 사용하면서 DB쿼리를 객체지향적으로 조작 가능
*쿼리문을 작성하는 양이 줄어 개발 비용 감소
*객체지향적으로 DB에 접근할 수 있어 가독성 높임
·재사용 및 유지보수가 편리
*객체들은 각 클래스로 나뉘어 있어 유지보수가 수월
*ORM을 통해 매핑된 객체는 모두 독립적으로 작성되어 있어 재사용이 용이
·데이터베이스에 대한 종속성 감소
*ORM을 통해 자동 생성된 SQL문은 객체 기반으로 DB테이블을 관리하기 때문에 DB에 종속적이지 않음
*DB교체시에도 비교적 적은 리스크
- ORM의 단점
·ORM만으로 온전한 서비스를 구현하는 것에 한계
*복잡한 서비스일 경우 직접 쿼리 구현하지 않고 코드로 구현하긴 어려움
*복잡한 쿼리를 정확한 설계없이 ORM만으로 구성하게되면 속도 저하등의 성능 문제 발생 가능성
·애플리케이션의 객체 관점과 DB의 관계 관점의 불일치 발생
*세분성 : ORM의 자동 설계 방법에 따라 DB테이블 수와 애플리케이션 앤티티 클래스 수가 다른 경우가 생김
-> 클래스가 테이블의 수보다 많아질 수 있음.
*상속성 : RDBMS에는 상속이라는 개념이 없음
*식별성 : RDBMS는 기본키로 동일성을 정의, 자바는 두 객체의 값이 같아도 다르다고 판단할 수 있음.
-> 식별과 동일성의 문제
*연관성 : 객체지향 언어는 객체를 참조함으로써 연고나성을 나타내지만 RDBMS에서는 외래키를 삽입함으로써 연관성을 표현. 또한 객체지향 언어에서 객체를 참조할 때는 방향성이 존재하지만 RDBMS에서 외래키 삽입하는 것은 양방향 관계를 가지기 때문에 방향성이 없음
*탐색 : 자바와 RDBMS는 어떤 값(객체)에 접근하는 방식이 다름. 자바에서는 특정 값 접근위해 객체 참조 같은 연결수단 활용. RDBMS에서는 쿼리를 최소화하고 조인을 통해 여러 테이블을 로드하고 값을 추출하는 접근방식
6.3 JPA
- JPA ? ) 자바 진영의 ORM 기술 표준으로 채택된 인터페이스의 모음. 실제로 동작하는 것은 아니고 어떻게 동작해야하는지 매커니즘을 정리한 표준 명세
내부적으로 JDBC를 사용함. 개발자가 직접 JDBC를 구현하면 SQL에 의존하게 되는 문제로 개발의 효율성이 떨어짐. JPA는 이 같은 문제를 보완해 개발자 대신 쿼리를 생성하고 DB를 조작해서 객체를 자동 매핑하는 역할 수행.
- JPA 기반의 구현체
1. Hibernate
2. EclipseLink
3. DataNucleus
이 중 가장 많이 사용되는 구현체는 Hibernate
6.4 하이버네이트
- 하이버네이트 : 자바의 ORM 프레임워크로 JPA가 정의하는 인터페이스를 구현하고 있는 JPA구현체 중 하나.
6.4.1 Spring Data JPA
- Spring Data JPA는 JPA를 편리하게 사용할 수 있도록 지원하는 스프링 하위 프로젝트 중 하나
CRUD 처리에 필욯안 인터페이스를 제공하며, 하이버네이트의 엔티티 매니저를 직접 다루지 않고 리포지토리를 정의해 사용함으로써 스프링이 적함한 쿼리를 동적으로 생성하는 방식으로 DB 조작.
6.5 영속성 컨텍스트
- 영속성 컨텍스트 : 애플리케이션과 DB 사이에서 엔티티와 레코드의 괴리를 해소하는 기능과 객체를 보관하는 기능 수행.
엔티티 객체가 영속성 컨텍스트에 들어오면 JPA는 엔티티 객체의 매핑 정보를 데이터베이스에 반영하는 작업 수행.
-> 엔티티 객체가 영속성 컨텍스트에 들어와서 JPA의 관리대상이 되는 시점부터 해당 엔티티 객체를 ==> 영속 객체
영속성 컨텍스트는 세션 단위의 생명주기를 가짐.
1. DB에 접근하기 위한 세션이 생성되면 영속성 컨텍스트가 만들어짐
2. 세션이 종료되면 영속성 컨텍스트도 없어짐.
-> 엔티티 매니저는 이런 과정에서 영속성 컨텍스트에 접근하기 위한 수단으로 사용
6.5.1 엔티티 매니저
- 엔티티 매니저 : 엔티티를 관리하는 객체
엔티티매니저는 데이터베이스에 접근해서 CRUD 작업을 수행.
Spring Data JPA를 사용하면 리포지토리를 사용해서 DB에 접근
실제 내부 구현체인 SimpleJpaRepository가 리포지토리에서 엔티티 메니저를 사용함.
- 엔티티 매니저 팩토리 : 엔티티 매니저를 만듦.
데이터베이스에 대응하는 객체로서 스프링 부트에서는 자동 설정기능이 있어 appilcation.properties에 설정으로 동작하는데 JPA의 구현체 중 하나인 하이버네이트에서는 persistence.xml이라는 설정파일을 구성하고 사용해야함.
엔티티 매니저 팩토리는 애플리케이션에서 단 하나만 생성되고 모든 엔티티가 공유해서 사용.
엔티티 매니저 팩토리로 생성된 엔티티 매니저는 엔티티를 영속성 컨텍스트에 추가해서 영속 객체로 만드는 작업을 수행하고, 영속성 컨텍스트와 DB를 비교하면서 실제 DB 대상으로 작업을 수행
6.5.2 엔티티의 생명주기
1. 비영속(New) : 영속성 컨텍스트에 추가되지 않은 엔티티 객체의 상태
2. 영속(Managed) : 영속성 컨텍스트에 의해 엔티티 객체가 관리되는 상태
3. 준영속(Detached) : 영속성 컨텍스트에 의해 관리되던 엔티티 객체가 컨텍스트와 분리된 상태
4. 삭제(Removed) : DB에서 레코드를 삭제하기 위해 영속성 컨텍스트에 삭제 요청을 한 상태
6.6 데이터베이스 연동
6.6.1 프로젝트 생성
Spring Data JPA의 의존성 추가하고 별도의 설정 필요.
application.properties에 연동할 DB정보 작성
6.7 엔티티 설계
JPA에서 엔티티는 데이터베이스의 테이블에 대응하는 클래스.
엔티티에는 DB에 쓰일 테이블과 컬럼을 정의.
엔티티에 어노테이션을 사용하면 테이블 간의 연관관계를 정의할 수 있음.
application.properties에 정의한 spring.jpa.hivernate.ddl-auto=create 로 하면 쿼리문을 작성하지 않아도 테이블이 자동생성됨.

실 프로젝트에서 application.yml에 정의했던 테이블 자동생성 옵션
6.7.1 엔티티 관련 기본 어노테이션
@Entity : 해당 클래스가 엔티티임을 명시. 클래스 자체는 테이블과 일대일 매칭. 해당 클래스의 인스턴스는 매핑되는 테이블에서하나의 레코드를 의미
@Table : 엔티티 클래스는 테이블과 매핑되므로 특별한 경우가 아니면 필요 없음. 사용하는 경우는 클래스 이름과 테이블 이름을 다르게 지정해야 하는 경우. 이 어노테이션이 없으면 클래스명==테이블 명 의미이고 다른 이름을 쓰려면 @Table(name = 값) 형태로 DB 테이블 명을 명시. 대체로 자바 명명법과 DB명명법이 다르기 때문에 자주 사용됨.
@Id : 엔티티 클래스의 필드는 테이블의 칼럼과 매핑. @Id 선언된 필드는 테이블의 기본값 역할로 사용. 모든 엔티티는 @Id가 꼭 필요함 !
@GeneratedValue : @Id와 함꼐 사용. 해당 필드의 값을 어떤 방식으로 자동 생성할지 결정.
- 사용 X : 직접할당. 애플리케이션에서 자체적으로 고유한 기본값을 생성할 경우 사용.
내부에 정해진 규칙에 의해 기본값을 생성하고 식별자로 사용함.
- AUTO : 기본 설정값. 기본값을 사용하는 DB에 맞게 자동 생성
- IDENTITY : 기본값 생성을 DB에 위임. DB의 AUTO_INCREMENT를 사용해 기본값 생성
- SEQUENCE : @SequenceGenerator 어노테이션으로 식별자 생성기를 설정하고 이를 통해 값을 자동 주입 받음
SwquenceGenerator를 정의할 때는 name, sequenceName, allocationSize 활용
@ GeneratedValue에 생성기를 설정
- TABLE : 어떤 DBMS를 사용하더라도 동일하게 동작하기 원할 경우 사용.
식별자로 사용할 숫자의 보관 테이블을 별도로 생성해서 엔티티를 생성할 때마다 값을 갱신하며 사용
@TableGenerator 어노테이션으로 테이블 정보를 설정
@Column : 엔티티 클래스의 필드는 자동으로 테이블 칼럼으로 배핑. 따라서 별다른 설정 안 할 때는 명시 안 해도 됨.
@Column에서 많이 사용하는 요소
- name : DB 컬럼명 설정 속성. 명시하지 않으면 자동으로 필드명으로 지정
- nullable : 레코드를 생성할 때 컬럼 값에 null처리가 가능한지 여부
- length : DB에 저장하는 데이터의 의최대 길이를 설정
- unique : 해당 컬럼을 유니크로 설정
@Transient : 엔티티 클래스에는 선언되어 있지만 DB에서 필요없을 경우
6.8 리포지토리 인터페이스 설계
스프링부트로 JpaRepository를 상속하는 인터페이스를 생성하면 기존 다양한 메서드를 손쉽게 사용 가능
6.8.1 리포지토리 인터페이스 생성
리포지토리는 엔티티가 생성한 DB에 접근하는데 사용.
여기서 말하는 리포지토리는 Spring Data JPA가 제공하는 인터페이스.
리포지토리 생성 : 접근하려는 테이블과 매핑되는 엔티티에 대한 인터페이스를 생성하고 JpaRepository를 상속받으면 됨.
@Repository
public interface MemberRepository extends JpaRepository<MemberEntity, Long> {
}
6.8.2 리포지토리 메서드 생성 규칙
CRUD에서 따로 생성해서 사용하는 메서드는 대부분 Read에 해당하는 Select 쿼리 밖에 없음.
엔티티 저장, 갱신, 삭제 할 때 별도의 규칙이 필요 없기 때문.
리포지토리에서 기본적으로 제공하는 조회 메소드는 기본값으로 단일 조회, 전체 엔티티 조회만 지원하기 때문에 필요에 따라 다른 조회 메서드 필요.
- 메서드에 이름 붙일 때는 첫 단어를 제외한 이후 단어들의 첫글자를 대문자로 설정
* FindBy : SQL문의 Where 절 역할을 수행 findBy 뒤에 엔티티의 필드 값을 입력해서 사용
ex) findByName(String name)
* AND, OR : 조건 여러 개 설정하기 위해 사용
ex) findByNameAndEmail(String name, String email)
* Like/NotLike : SQL문의 like와 동일 기능 수행. 특정 문자를 포함하는지 여부를 조건으로 추가.
비슷한 키워드 : Containing, Contains, isContaing
* StartsWith/StartingWith : 특정 키워드로 시작하는 문자열 조건 설정
* EndsWith/EndingWith : 특정 키워드로 끝나는 문자열 조건 설정
* IsNull/IsNotNull : 레코드 값이 Null이거나 Null이 아닌 값을 검색
* True/False : Boolean 타입 레코드 검색에 사용
* Before/After : 시간 기준으로 값을 검색
* LessThan/GreaterThan : 특정 값(숫자) 기준으로 대소 비교할 때 사용
* Between : 두 값(숫자) 사이의 데이터 조회
* OrderBy : SQL 문에서 order by와 동일한 기능을 수행.
ex) 가격순 이름 조회 : List<Product> findByNameOrderByPriceAsc(Stringg name);
* countBy : SQL문의 count와 동일한 기능 수행. 결과 갑의 개수(count)추출.
6.9 DAO 설계
DAO는 DB에 접근하기 위한 로직을 관리하기 위한 객체.
비즈니스 로직의 동작 과정에서 데이터를 조작하는 기능은 DAO객체가 수행.
다만 Spring Data JPA에서 DAO의 개념은 리포지토리가 대체.
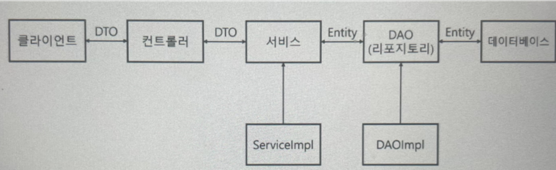
DB와 밀접한 관련이 있는 레이어까지는 엔티티 객체를 사용하고, 클라이언트와 가까워지는 레이어에서는 DTO객체를 사용하는 것이 일반적. 다만 그룹내 규정에 따라 달라질 수 있음.
이 프로젝트에서는 컨트롤러 - 서비스 -DAO -리포지토리 - DB 의 구조로 요청과 응답이 주고받아짐.
롬복의 주요 어노테이션
- @Getter, @Setter
- 생성자 자동 생성 어노테이션
@AllArgsConstructor : 모든 필드를 매개변수로 갖는 생성자를 자동 생성
@NoArgsConstructor : 매개 변수가 없는 생성자를 자동 생성
@RequiredArgsConstructor : 필드 중 final이나 @NotNull이 설정된 변수를 매개 변수로 갖는 생성자를 자동 생성.
- @ToString : toString() 메서드를 생성하는 어노테이션.
@ToString(exclude = "name") 을 통해 특정 필드를 자동 생성에서 제외 할 수 있음.
- @EqualsAndHashCode : 객체의 동등성(Equality)와 동일성(Identity)를 비교하는 연산 메서드 수행.
* equals : 두 객체의 내용이 같은지 동등성 비교
* hashCode : 두 객체가 같은 객체인지 동일성 비교
- @Data : @Getter/@Setter, @ToString, @RequiredArgsConstructor, @EqualsAndHashCode를 모두 포함
'부캠 > 블로그 과제' 카테고리의 다른 글
| 스프링 핵심가이드) 북스터디 5주차 : 09장 (0) | 2023.10.20 |
|---|---|
| 스프링 핵심가이드) 북스터디 4주차 : 08장 Spring Data JPA (0) | 2023.10.16 |
| 스프링 핵심가이드) 북스터디 2주차 : 04~05장 API를 작성하는 다양한 방법 (0) | 2023.09.30 |
| 스프링 핵심가이드) 북스터디 1주차 : 02~03장 (0) | 2023.09.24 |
| 스프링 핵심가이드) 북스터디 1주차 : 01장 (0) | 2023.09.24 |